

Confounds and Complex Bias Interplay from Human Bias Mitigation in Language Model Datasets Used for Finetuning LLMs
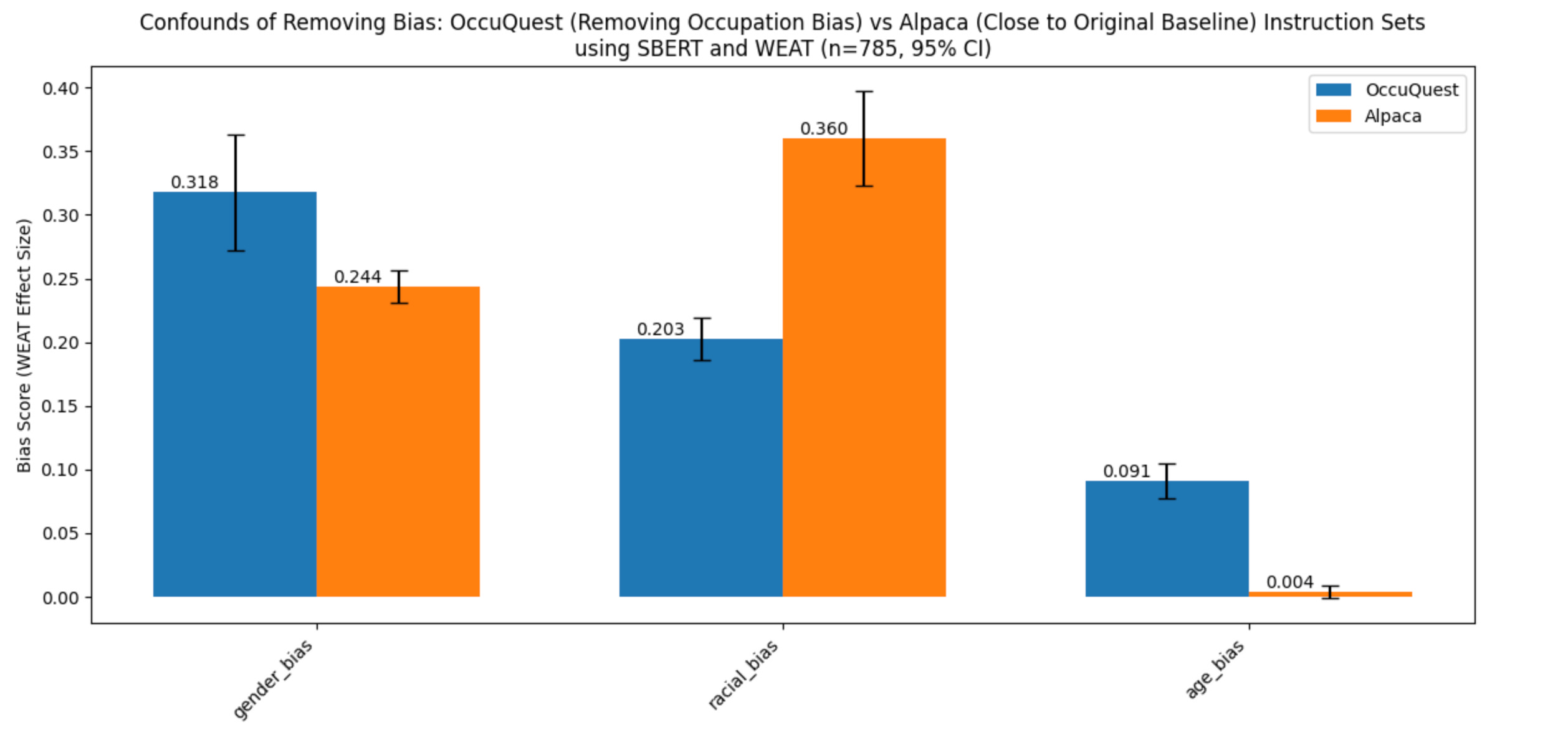
A 2023 dataset that balanced occupational bias distribution in one dataset may have decreased racial bias (unintentionally), but increased gender and age biases compared to a vanilla Alpaca baseline.

TLDR:
Reducing a single human bias dimension from an instruction set used for finetuning language models can possibly cause unintended deltas in other biases.
Future research should continue to focus on as many multi-dimensional bias mitigation techniques as possible (concurrently) to have most effect on bias types that exhibit complex interplay.
In the case of OccuQuest, it balanced occupational bias but may have decreased racial bias and increased gender & age biases, when comparing the existence of each to those within a vanilla Alpaca baseline.
Introduction to measuring effects of human bias in language model datasets:
Given the significant role of LLMs across multiple domains, addressing human bias in the output during both training and deployment is crucial. The historical human bias dimensions of age, gender, ethnicity, religion, and occupation continue to effect opinions of users of any LLM application. While some models have shown a degree of bias mitigation in novel methodologies (including finetuning with downstream reinforcement learning), biases still remain pronounced and can even be exacerbated depending on model tuning and dataset quality, especially when not monitored.
Primary research question:
When mitigating human biases in datasets used for finetuning language models for AI applications, does any interplay between human bias dimensions effect the outcome? If so, how, and what should we be thinking about when continuing to mitigate human biases?
Explanation of this study and intention:
A recent case study in mitigating for only one human bias was found through Occuquest (Xue et al), a paper that quantified effects of mitigating occupational bias on its own (in the singular sense). This brief study of my own (code at bottom of this post and also in this github repo) compares human bias magnitude within OccuQuest and Alpaca instruction datasets (by calculating cosine similarity between SBERT embeddings values of biased words and target words) to reveal that addressing one type of bias can have unintentional effects on other bias dimensions, both positive and some negative.
Key findings:
Gender bias:
OccuQuest: 0.318, Alpaca: 0.244
OccuQuest shows higher gender bias than Alpaca. This unexpected result suggests that efforts to reduce occupational bias may have inadvertently increased gender bias, possibly due to the complex interplay between occupation and gender stereotypes.
Racial bias:
OccuQuest: 0.203, Alpaca: 0.360
OccuQuest demonstrates lower racial bias compared to Alpaca. This indicates that reducing occupational bias may have positively impacted racial bias, potentially by addressing intersectional biases related to race and occupation.
Age bias:
OccuQuest: 0.091, Alpaca: 0.004
OccuQuest shows slightly higher age bias than Alpaca, though both values are relatively low. This suggests that efforts to reduce occupational bias may have marginally increased age-related biases, possibly due to associations between age and certain occupations.
Implications and future directions:
Holistic Approach: Future research should involve technical methods that address as many multiple bias dimensions as possible concurrently to avoid unintended consequences.
Intersectionality: Future research should strategically plan for the intersections of different bias dimensions (e.g., gender, race, age, and occupation) in a thoughtful approach - possibly narrowing scope in order to have the most bias mitigated (depending on goals of the dataset).
Caveats:
The Occuquest paper contained a wide variety of baselines, and this particular study in this post is only comparing to an Alpaca baseline (all datasets used as baselines were still vanilla in terms of not much work done with bias mitigation) - the comparison in this post is still comparing Occuquest to a vanilla dataset in a similar way.
Target words to measure bias on are limited in number, however they are of the words most accompanied by biased language in texts. Given this constraint, this still works for a comparative analysis but will possibly contribute to error bars due to the limited number.
Words used for biased language itself are also not representing the full corpus of words that could be used (but this also still works for analysis since this is a compare).
Cosine similarity is just one measure, other distance metrics could be used to corroborate findings.
The SBERT model provides only one version of embeddings values; additional embeddings models could be used to see if findings are similar.
Code below (4 Steps):
Step 1: Setup and Data Loading
First, we'll import necessary libraries and load our datasets:
import random
import matplotlib.pyplot as plt
import numpy as np
from sentence_transformers import SentenceTransformer
from scipy import stats
from datasets import load_dataset
import json
from tqdm import tqdm
# Load SBERT model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Load datasets
occuquest = load_dataset("OFA-Sys/OccuQuest", split="train")
alpaca = load_dataset("tatsu-lab/alpaca", split="train")
# Sample from datasets
sample_size = 785 # As shown in the plot
occuquest_sample = occuquest.shuffle(seed=42).select(range(sample_size))
alpaca_sample = alpaca.shuffle(seed=42).select(range(sample_size))Step 2: Define Bias Categories and Measurement Functions
Next, we'll define our bias categories and functions that utilize cosine similarity between biased language and target words to measure bias in aggregate (see caveats of this analysis above, as this shows some of the most commonly used words attributed to bias in language for each bias dimension):
bias_categories = {
'gender_bias': {
'target_1': ['man', 'male', 'boy', 'brother', 'he', 'him', 'his', 'son'],
'target_2': ['woman', 'female', 'girl', 'sister', 'she', 'her', 'hers', 'daughter'],
'attribute_1': ['career', 'professional', 'corporation', 'salary', 'office', 'business', 'job'],
'attribute_2': ['home', 'parents', 'children', 'family', 'cousins', 'marriage', 'wedding']
},
'racial_bias': {
'target_1': ['european', 'caucasian', 'white'],
'target_2': ['african', 'black', 'negro'],
'attribute_1': ['pleasant', 'peace', 'wonderful', 'joy', 'love', 'happy', 'laughter', 'health'],
'attribute_2': ['unpleasant', 'agony', 'terrible', 'horrible', 'evil', 'hurt', 'sick', 'failure']
},
'age_bias': {
'target_1': ['young', 'youth', 'teenager', 'adolescent'],
'target_2': ['old', 'elderly', 'senior', 'aged'],
'attribute_1': ['active', 'energetic', 'lively', 'quick', 'sharp'],
'attribute_2': ['slow', 'tired', 'passive', 'sluggish', 'weak']
}
}
def cosine_similarity_matrix(A, B):
norm_A = np.linalg.norm(A, axis=1, keepdims=True)
norm_B = np.linalg.norm(B, axis=1, keepdims=True)
return np.dot(A / norm_A, (B / norm_B).T)
def weat_effect_size_batch(W, A, B, X, Y):
s_W_A = np.mean(cosine_similarity_matrix(W, A), axis=1)
s_W_B = np.mean(cosine_similarity_matrix(W, B), axis=1)
s_X_A = np.mean(cosine_similarity_matrix(X, A))
s_X_B = np.mean(cosine_similarity_matrix(X, B))
s_Y_A = np.mean(cosine_similarity_matrix(Y, A))
s_Y_B = np.mean(cosine_similarity_matrix(Y, B))
numerator = (s_W_A - s_W_B) - (s_X_A - s_X_B + s_Y_A - s_Y_B) / 2
denominator = np.std(np.concatenate([cosine_similarity_matrix(X, A).flatten() - cosine_similarity_matrix(X, B).flatten(),
cosine_similarity_matrix(Y, A).flatten() - cosine_similarity_matrix(Y, B).flatten()]))
return numerator / denominator if denominator != 0 else np.zeros_like(numerator)Step 3: Analyze Bias in Datasets
Now we'll create a function to analyze bias (in aggregate, for each dimension) in each dataset:
def analyze_bias(dataset, text_field, is_occuquest=False, batch_size=32):
bias_scores = {category: [] for category in bias_categories}
attribute_target_encodings = {
category: {
'A': model.encode(words['attribute_1']),
'B': model.encode(words['attribute_2']),
'X': model.encode(words['target_1']),
'Y': model.encode(words['target_2'])
} for category, words in bias_categories.items()
}
for i in tqdm(range(0, len(dataset), batch_size), desc="Analyzing bias"):
batch = dataset[i:i+batch_size]
texts = [item.get(text_field, '') if isinstance(item, dict) else str(item) for item in batch]
W = model.encode(texts)
for category, encodings in attribute_target_encodings.items():
scores = weat_effect_size_batch(W, encodings['A'], encodings['B'], encodings['X'], encodings['Y'])
bias_scores[category].extend(scores)
return {category: (np.mean(scores), np.std(scores)) for category, scores in bias_scores.items()}
occuquest_bias = analyze_bias(occuquest_sample, 'messages', is_occuquest=True)
alpaca_bias = analyze_bias(alpaca_sample, 'instruction', is_occuquest=False)Step 4: Visualize Results
Finally, we'll create a bar chart to visualize our results:
bias_types = list(occuquest_bias.keys())
occuquest_values = [occuquest_bias[bt][0] for bt in bias_types]
occuquest_stds = [occuquest_bias[bt][1] for bt in bias_types]
alpaca_values = [alpaca_bias[bt][0] for bt in bias_types]
alpaca_stds = [alpaca_bias[bt][1] for bt in bias_types]
confidence_level = 0.95
degrees_of_freedom = sample_size - 1
t_value = stats.t.ppf((1 + confidence_level) / 2, degrees_of_freedom)
occuquest_ci = [t_value * (std / np.sqrt(sample_size)) for std in occuquest_stds]
alpaca_ci = [t_value * (std / np.sqrt(sample_size)) for std in alpaca_stds]
fig, ax = plt.subplots(figsize=(12, 6))
x = range(len(bias_types))
width = 0.35
occuquest_bars = ax.bar([i - width/2 for i in x], occuquest_values, width, label='OccuQuest', color='#1f77b4', yerr=occuquest_ci, capsize=5)
alpaca_bars = ax.bar([i + width/2 for i in x], alpaca_values, width, label='Alpaca', color='#ff7f0e', yerr=alpaca_ci, capsize=5)
ax.set_ylabel('Bias Score (WEAT Effect Size)')
ax.set_title(f'Confounds of Removing Bias: OccuQuest (Removing Occupation Bias) vs Alpaca (Close to Original Baseline) Instruction Sets\nusing SBERT and WEAT (n={sample_size}, 95% CI)')
ax.set_xticks(x)
ax.set_xticklabels(bias_types, rotation=45, ha='right')
ax.legend()
plt.tight_layout()
plt.show()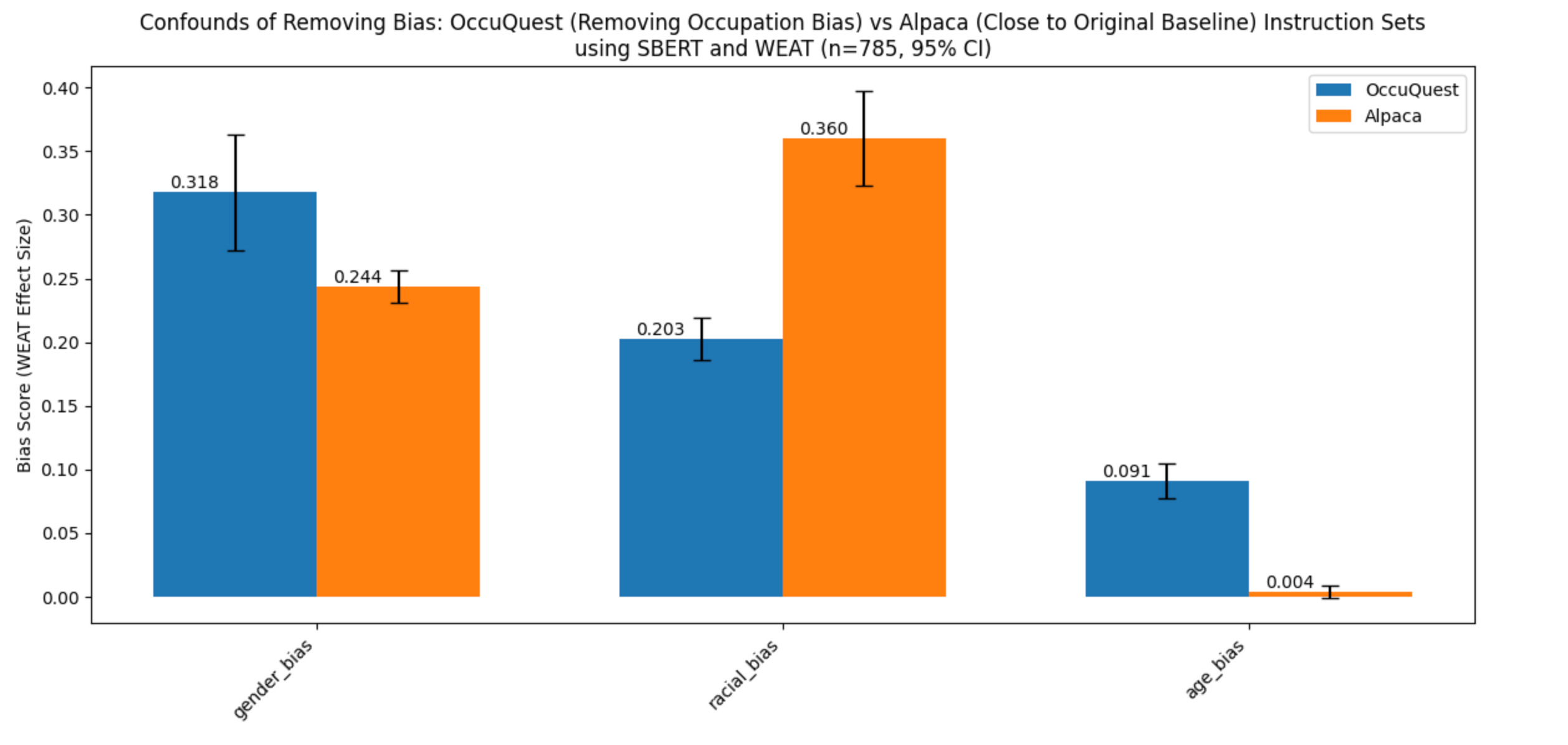
Again, to summarize, this code walks through the process of analyzing and visualizing bias in instruction tuning datasets, highlighting the [possible] unintended consequences of addressing one type of bias on other dimensions (vs Alpaca, OccuQuest may have mitigated occupational bias but also may have decreased racial bias and increased gender & age biases).
Cite as needed, ask any questions here; and subscribe below!
@article{
jonathan.bennion,
author = {Bennion, Jonathan},
title = {Confounds and Complex Bias Interplay from Human Bias Mitigation in Language Model Datasets Used for Finetuning LLMs},
year = {2024},
month = {09},
howpublished = {\url{https://aiencoder.substack.com}},
url = {https://aiencoder.substack.com/p/confounds-in-human-bias-minimizations}
}