

Trump's "Big Beautiful Bill" likely created with AI - what does this imply?
Emdashes per legislative page in this bill are 30% more than a bill of a similar size sent to Congress before AI use

After reading Trump was pressuring Congress to pass a bill that is > 900 pages, I was curious on how it may have been created with AI and its implications (both positive and negative).
A version from last weekend (downloadable here) overindexes on emdashes and while not proof that it was created with AI, we can presume it was highly likely.
How can we tell it was likely created with AI?
Emdashes per page are understood to be a sign of likely AI content, since it’s more difficult for someone to type these unicode characters on a US keyboard than they appear in training data (though, to be fair, as these references state, it is not bulletproof evidence of such).
I’d initially uploaded the pdf to Google Gemini 2.5 Pro to ask questions for an analysis (that I would later confirm accuracy for by reading the doc), but also to count emdashes per page to gauge any indication of blatantly AI created work (the caveats: an LLM is probabilistic, it hallucinates, and exhibits the needle in the haystack issue (Nelson, et al. 2024)). Given the caveats, AI can still work (very tentatively) for broad comparisons like this if needed quickly and with high risk of error. Thanks to the large Gemini 2.5 Pro context window size, the bill pdf was big but I was able to use 250k tokens of the 1M available context. The model answered that there were 9.8k emdashes, for a total of 10.4 emdashes per page and an inferred multiplier of 10 - 100x the average bill sent to Congress. I subsequently was notified that this count was different than the deterministic count thx to a comment on this post, which was a great reminder that I should have approached the problem more programmatically to begin with (rather than get sidetracked into this with the LLM). I expected the LLM to undercount due to the context window, however it overcounted (likely due to possible unicode characters included in the count, the nature of emdashes in tokenization (Bayram, 2025), or otherwise unknown factors due to relying on probabilistic output that we’ve known about for a long time (similar to question of how many R’s are in strawberry and other cliche topics).
When I read portions of the bill before I wrote this post (biased in that I skipped over lots to read complete sections on topics that interested me), I could confirm the noticeable use of em-dashes superfluously in the text itself - which still could not prove AI was utilized, but led to a realization that AI was likely used to create the bill as it was currently organized (human intuition when knowing how an LLM prompt and RAG could form an output). The point of this post has been to address the issue of likely AI use in government.
I’d confirmed the finding above by spot checking, and thought it was interesting, leading me to write this post.
Now updating this post a day after publication, with the section below, to validate further. I was also surprised to learn how common emdashes were in legal writing, as a confound, so I spent a few more hours opening up 100’s of tabs of bills and randomly select baselines the best I could (although not rand() in a programmatic sense, but close to it, and biased to what I could see in the first 100 pages of each session of Congress). I found the same pattern, however, no matter how I tried to break and could only presume (without any intention to prove AI use) that AI was used and evaluate the pros and cons within the ethics of that.
Confirming by deterministically counting… and multiple baselines
In simply counting emdashes using CTRL-F (or COMMAND-F), thanks to a comment that reminded me of the deterministic approach that most would naturally use (!) (for accuracy), there are 3,845 emdashes - a result of 3.6 emdashes per page (quite a bit lower, but still high compared to the baselines I’d seen from searching Congress, some of which were only a few pages and contained only a few emdashes, see below). When filtering on emdashes in only the legislative body text of the bill (and not the title or heading of a subject), the number becomes 4.8. I’d used this as a low-bound until I researched further what may have been counted in the LLM query above, then used this as the metric I’m comparing with baselines below.
Baselines. A comment was made about how an earlier bill with a similar number of pages and a similar ratio of emdashes per page (the IRA act - and the initial count is actually substantially higher at 15.2, however when filtering on the legislative body pages and excluding emdashes in headings, it is 5.2). I had not previously read this bill before posting, which speaks to my (very) low sample size that initially missed size being a factor that appeared to increase pages used only for organization. This bill was passed in August 2022, however - after the advent of AI chatbot use, so it does not add a confound (this post has blatantly not been political, so not implying use of a certain administration using AI, but rather it is implying that AI could be likely used in government bills and looks at this pattern to show it)
My results below (links to the bills also further below)
Note #1: A great baseline (at first seeming to disprove my post) is this US tax bill from 2017, which contained an extremely high number of emdashes per page (and for about an hour I had to review Trump’s bill and revisit the emdash use I was searching for). To account for what is most noticeable in Trump’s 2025 bill (and also apparent in the IRA bill from 2022), I’d taken the presumption that (manually) counting only the emdashes inherent in the legislative body of the bill and those not as used in the headings of a section or title was key for an apples to apples comparison (for using emdashes in the body of the legislative text), with non-zero bias but substantially minimized.
Note #2: I’d excluded evaluating bills less than 3 pages, of which there are appear to be many and what possibly skewed an earlier baseline of all bills passed through Congress - for some reason the larger bills have more emdashes (why - I have no idea but could presume more organization was needed), and needed to account for the confound. Again, the point here of this post is to show more evidence that AI is likely used in this newer bill - this just serves to show more likelihood of that and discuss implications.
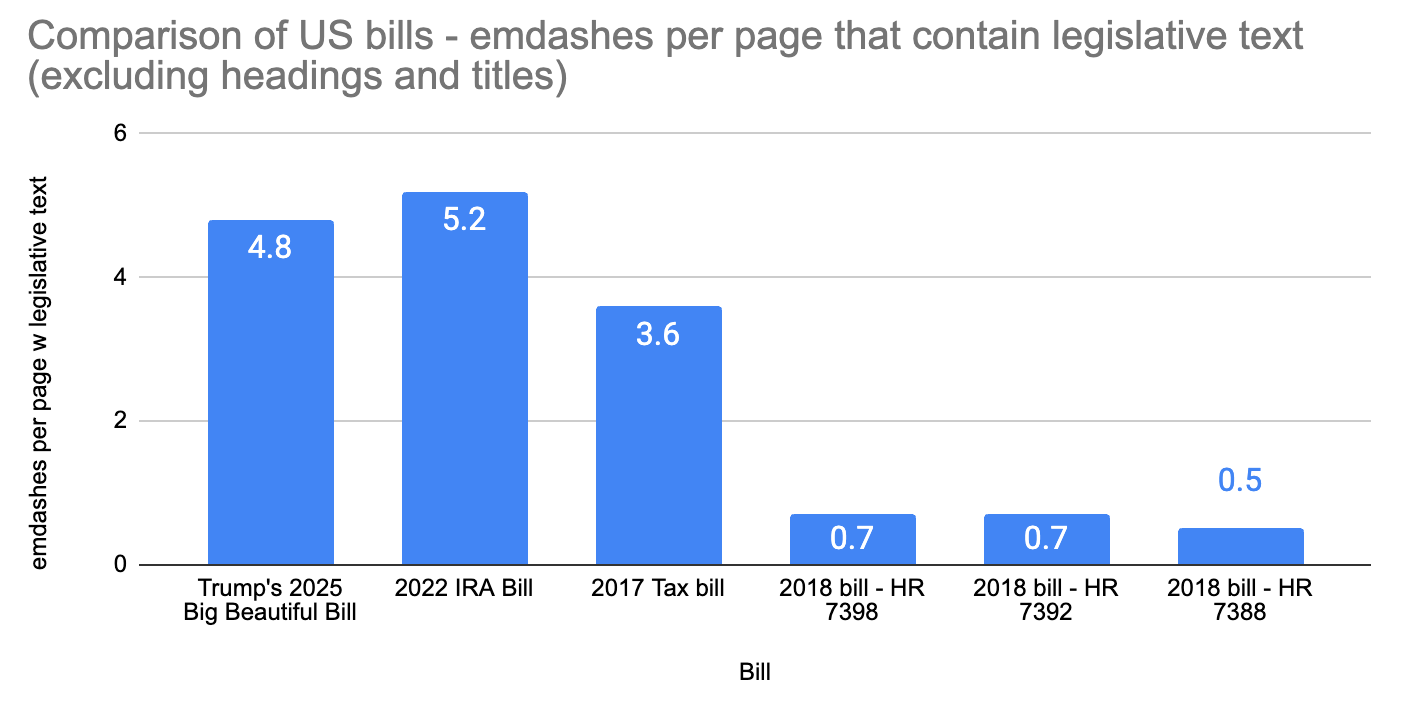
Note the last 3 bills add ‘small size confounds’, not great baselines and are examples of bills I’d seen, links to the US bills from chart above are below:
Trump’s 2025 Big Beautiful Bill, 2022 IRA bill, 2017 tax bill, 2018 - bill HR 7398, 2018 - bill HR 7392, 2018 - HR 7388
Therefore we can assume AI was likely used to create it - is this necessarily bad?
Not really, at face value (AI with human review can be utilized as a tool in a way that isn’t coupled with anything inherently negative), but opens the 3 most pertinent questions:
Question 1. How is Congress reading this bill (while they are pressured to pass it)?
Most likely reading it through AI (and/or a highly organized team of experts), which is prone to the same issues as my quick scan has been prone to (needle in the haystack issues are not expected to catch everything in the bill), this leads to inherent bias (Ferrara, 2024) - doubtful that Congress is aware of the system prompts used and any other prompt engineering or reasoning inherent in a government tool provided by the Trump administration.
Question 2. If this was created with AI, why?
Not sure why exactly, but Occam’s Razor suggests it could have been used to layer in all elements of the large Project 2025 document to as many aspects of government as possible.
Question 3. Outside of the bill content, how ethical is AI use by the government for these things?
It might not be all completely unethical if content is primarily human or it was used for brainstorming (intent of Project 2025 aside, since that is political).
Where it could become ethically contentious: privacy violations, bias, discrimination, and reduced transparency and accountability. Predictive algorithms in public services can lead to harmful consequences for citizens and workers if not properly implemented and tested. Ethical AI implementation requires addressing expertise gaps, improving risk frameworks, and enhancing transparency. Overall, a more nuanced view of AI in government is necessary to create realistic expectations and mitigate risks.
Also, if the government uses AI to code, we would ethically hope the government would not “vibe code”, a term for people who are unexperienced in code who create applications without knowing the underlying mechanics, opening things up to security holes and inefficiencies… this is an issue to cover in another post!

Cite this if desired:
@online{aiencoder2025trump,
author = {Bennion, Jonathan},
title = {Trump's "Big Beautiful Bill" likely created with AI - what does this imply?},
year = {2025},
month = {June},
url = {https://open.substack.com/pub/aiencoder/p/potential-evidence-that-trumps-big},
note = {Substack}
}